
-1-1.jpg)
I’ve long thought that there was an opportunity to improve the way we think about internal links, and to make much more effective recommendations. I feel like, as an industry, we have done a decent job of making the case that internal links are important and that the information architecture of big sites, in particular, makes a massive difference to their performance in search.
And yet we’ve struggled to dig deeper than finding particularly poorly-linked pages, and obviously-bad architectures, leading to recommendations that are hard to implement, with weak business cases.
I’m going to propose a methodology that:
- Incorporates external authority metrics into internal PageRank (what I’m calling “local PageRank”) to take pure internal PageRank which is the best data-driven approach we’ve seen for evaluating internal links and avoid its issues that focus attention on the wrong areas
- Allows us to specify and evaluate multiple different changes in order to compare alternative approaches, figure out the scale of impact of a proposed change, and make better data-aware recommendations
Current information architecture recommendations are generally poor
Over the years, I’ve seen (and, ahem, made) many recommendations for improvements to internal linking structures and information architecture. In my experience, of all the areas we work in, this is an area of consistently weak recommendations.
I have often seen:
- Vague recommendations - (“improve your information architecture by linking more to your product pages”) that don’t specify changes carefully enough to be actionable
- No assessment of alternatives or trade-offs - does anything get worse if we make this change? Which page types might lose? How have we compared approach A and approach B?
- Lack of a model - very limited assessment of the business value of making proposed changes - if everything goes to plan, what kind of improvement might we see? How do we compare the costs of what we are proposing to the anticipated benefits?
This is compounded in the case of internal linking changes because they are often tricky to specify (and to make at scale), hard to roll back, and very difficult to test (by now you know about our penchant for testing SEO changes - but internal architecture changes are among the trickiest to test because the anticipated uplift comes on pages that are not necessarily those being changed).
In my presentation at SearchLove London this year, I described different courses of action for factors in different areas of this grid:
-1-1.png)
It’s tough to make recommendations about internal links because while we have a fair amount of data about how links generally affect rankings, we have less information specifically focusing on internal links, and so while we have a high degree of control over them (in theory it’s completely within our control whether page A on our site links to page B) we need better analysis:
-1-1.png)
The current state of the art is powerful for diagnosis
If you want to get quickly up to speed on the latest thinking in this area, I’d strongly recommend reading these three articles and following their authors:
- Calculate internal PageRank by Paul Shapiro
- Using PageRank for internal link optimisation by Jan-Willem Bobbink
- Easy visualizations of PageRank and page groups by Patrick Stox
A load of smart people have done a ton of thinking on the subject and there are a few key areas where the state of the art is powerful:
-1-1.png)
There is no doubt that the kind of visualisations generated by techniques like those in the articles above are good for communicating problems you have found, and for convincing stakeholders of the need for action. Many people are highly visual thinkers, and it’s very often easier to explain a complex problem with a diagram. I personally find static visualisations difficult to analyse, however, and for discovering and diagnosing issues, you need data outputs and / or interactive visualisations:
-1-1.png)
But the state of the art has gaps:
The most obvious limitation is one that Paul calls out in his own article on calculating internal PageRank when he says:
“we see that our top page is our contact page. That doesn’t look right!”
This is a symptom of a wider problem which is that any algorithm looking at authority flow within the site that fails to take into account authority flow into the site from external links will be prone to getting misleading results. Less-relevant pages seem erroneously powerful, and poorly-integrated pages that have tons of external links seem unimportant in the pure internal PR calculation.
In addition, I hinted at this above, but I find visualisations very tricky - on large sites, they get too complex too quickly and have an element of the Rorschach to them:
-1-1.png)
My general attitude is to agree with O’Reilly that “Everything looks like a graph but almost nothing should ever be drawn as one”:
-1-1.png)
All of the best visualisations I’ve seen are nonetheless full link-graph visualisations - you will very often see crawl-depth charts which are in my opinion even harder to read and obscure even more information than regular link graphs. It’s not only the sampling but the inherent bias of only showing links in the order discovered from a single starting page - typically the homepage - which is useful only if that’s the only page on your site with any external links. This Sitebulb article talks about some of the challenges of drawing good crawl maps:
-1-1.png)
But by far the biggest gap I see is the almost total lack of any way of comparing current link structures to proposed ones, or for comparing multiple proposed solutions to see a) if they fix the problem, and b) which is better. The common focus on visualisations doesn’t scale well to comparisons - both because it’s hard to make a visualisation of a proposed change and because even if you can, the graphs will just look totally different because the layout is really sensitive to even fairly small tweaks in the underlying structure.
Our intuition is really bad when it comes to iterative algorithms
All of this wouldn’t be so much of a problem if our intuition was good. If we could just hold the key assumptions in our heads and make sensible recommendations from our many years of experience evaluating different sites.
Unfortunately, the same complexity that made PageRank such a breakthrough for Google in the early days makes for spectacularly hard problems for humans to evaluate. Even more unfortunately, not only are we clearly bad at calculating these things exactly, we’re surprisingly bad even at figuring them out directionally. [Long-time readers will no doubt see many parallels to the work I’ve done evaluating how bad (spoiler: really bad) SEOs are at understanding ranking factors generally].
I think that most people in the SEO field have a high-level understanding of at least the random surfer model of PR (and its extensions like reasonable surfer). Unfortunately, most of us are less good at having a mental model for the underlying eigenvector / eigenvalue problem and the infinite iteration / convergence of surfer models is troublesome to our intuition, to say the least.
I explored this intuition problem recently with a really simplified example and an unscientific poll:
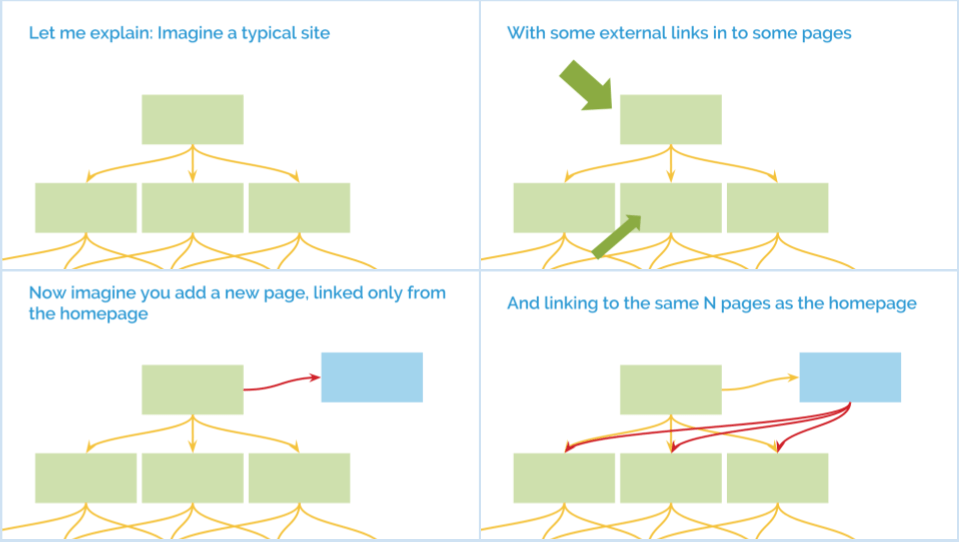
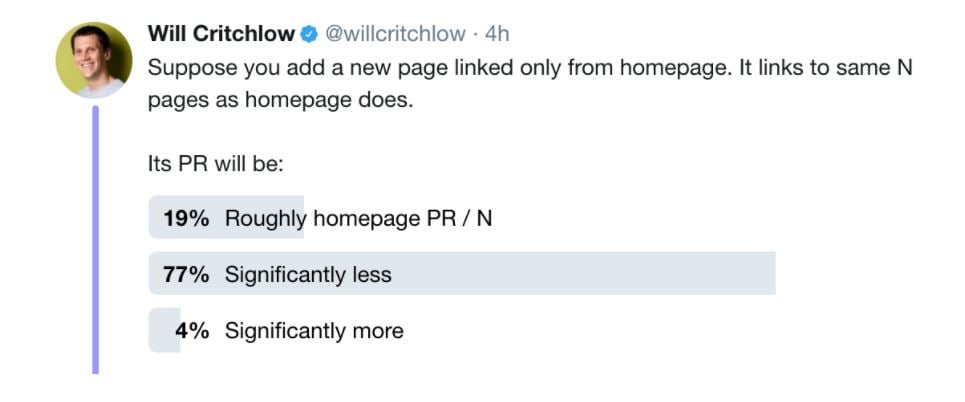
The results were unsurprising - over 1 in 5 people got even a simple question wrong (the right answer is that a lot of the benefit of the link to the new page flows on to other pages in the site and it retains significantly less than an Nth of the PR of the homepage):
I followed this up with a trickier example and got a complete lack of consensus:
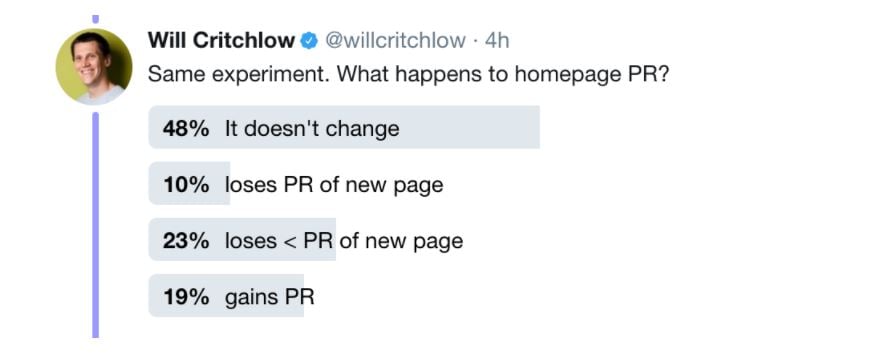
The right answer is that it loses (a lot) less than the PR of the new page except in some weird edge cases (I think only if the site has a very strange external link profile) where it can gain a tiny bit of PR. There is essentially zero chance that it doesn’t change, and no way for it to lose the entire PR of the new page.
Most of the wrong answers here are based on non-iterative understanding of the algorithm. It’s really hard to wrap your head around it all intuitively (I built a simulation to check my own answers - using the approach below).
All of this means that, since we don’t truly understand what’s going on, we are likely making very bad recommendations and certainly backing them up and arguing our case badly.
Doing better part 1: local PageRank solves the problems of internal PR
In order to be able to compare different proposed approaches, we need a way of re-running a data-driven calculation for different link graphs. Internal PageRank is one such re-runnable algorithm, but it suffers from the issues I highlighted above from having no concept of which pages it’s especially important to integrate well into the architecture because they have loads of external links, and it can mistakenly categorise pages as much stronger than they should be simply because they have links from many weak pages on your site.
In theory, you get a clearer picture of the performance of every page on your site - taking into account both external and internal links - by looking at internet-wide PageRank-style metrics. Unfortunately, we don’t have access to anything Google-scale here and the established link data providers have only sparse data for most websites - with data about only a fraction of all pages.
Even if they had dense data for all pages on your site, it wouldn’t solve the re-runnability problem - we wouldn’t be able to see how the metrics changed with proposed internal architecture changes.
What I’ve called “local” PageRank is an approach designed to attack this problem. It runs an internal PR calculation with what’s called a personalization vector designed to capture external authority weighting. This is not the same as re-running the whole PR calculation on a subgraph - that’s an extremely difficult problem that Google spent considerable resources to solve in their caffeine update. Instead, it’s an approximation, but it’s one that solves the major issues we had with pure internal PR of unimportant pages showing up among the most powerful pages on the site.
Here’s how to calculate it:
-1-1.png)
The next stage requires data from an external provider - I used raw mozRank - you can choose whichever provider you prefer, but make sure you are working with a raw metric rather than a logarithmically-scaled one, and make sure you are using a PageRank-like metric rather than a raw link count or ML-based metric like Moz’s page authority:
-1-1.png)
You need to normalise the external authority metric - as it will be calibrated on the entire internet while we need it to be a probability vector over our crawl - in other words to sum to 1 across our site:
-1-1.png)
We then use the NetworkX PageRank library to calculate our local PageRank - here’s some outline code:
What’s happening here is that by setting the personalization parameter to be the normalised vector of external authorities, we are saying that every time the random surfer “jumps”, instead of returning to a page on our site with uniform random chance, they return with probabilities proportional to the external authorities of those pages. This is roughly like saying that any time someone leaves your site in the random surfer model, they return via the weighted PageRank of the external links to your site’s pages. It’s fine that your external authority data might be sparse - you can just set values to zero for any pages without external authority data - one feature of this algorithm is that it’ll “fill in” appropriate values for those pages that are missing from the big data providers’ datasets.
In order to make this work, we also need to set the alpha parameter lower than we normally would (this is the damping parameter - normally set to 0.85 in regular PageRank - one minus alpha is the jump probability at each iteration). For much of my analysis, I set it to 0.5 - roughly representing the % of site traffic from external links - approximating the idea of a reasonable surfer.
There are a few things that I need to incorporate into this model to make it more useful - if you end up building any of this before I do, please do let me know:
- Handle nofollow correctly (see Matt Cutts’ old PageRank sculpting post)
- Handle redirects and rel canonical sensibly
- Include top mR pages (or even all pages with mR) - even if they’re not in the crawl that starts at the homepage
- You could even use each of these as a seed and crawl from these pages
- Use the weight parameter in NetworkX to weight links by type to get closer to reasonable surfer model
- The extreme version of this would be to use actual click-data for your own site to calibrate the behaviour to approximate an actual surfer!
Doing better part 2: describing and evaluating proposed changes to internal linking
After my frustration at trying to find a way of accurately evaluating internal link structures, my other major concern has been the challenges of comparing a proposed change to the status quo, or of evaluating multiple different proposed changes. As I said above, I don’t believe that this is easy to do visually as most of the layout algorithms used in the visualisations are very sensitive to the graph structure and just look totally different under even fairly minor changes. You can obviously drill into an interactive visualisation of the proposed change to look for issues, but that’s also fraught with challenges.
So my second proposed change to the methodology is to find ways to compare the local PR distribution we’ve calculated above between different internal linking structures. There are two major components to being able to do this:
-
Efficiently describing or specifying the proposed change or new link structure; and
-
Effectively comparing the distributions of local PR - across what is likely tens or hundreds of thousands of pages
How to specify a change to internal linking
I have three proposed ways of specifying changes:
1. Manually adding or removing small numbers of links
Although it doesn’t scale well, if you are just looking at changes to a limited number of pages, one option is simply to manipulate the spreadsheet of crawl data before loading it into your script:
-1-1.png)
2. Programmatically adding or removing edges as you load the crawl data
Your script will have a function that loads the data from the crawl file - and as it builds the graph structure (a DiGraph in NetworkX terms - which stands for Directed Graph). At this point, if you want to simulate adding a sitewide link to a particular page, for example, you can do that - for example if this line sat inside the loop loading edges, it would add a link from every page to our London SearchLove page:
site.add_edges_from([(edge['Source'], 'https://www.distilled.net/events/searchlove-london/')])
You don’t need to worry about adding duplicates (i.e. checking whether a page already links to the target) because a DiGraph has no concept of multiple edges in the same direction between the same nodes, so if it’s already there, adding it will do no harm.
Removing edges programmatically is a little trickier - because if you want to remove a link from global navigation, for example, you need logic that knows which pages have non-navigation links to the target, as you don’t want to remove those as well (you generally don’t want to remove all links to the target page). But in principle, you can make arbitrary changes to the link graph in this way.
3. Crawl a staging site to capture more complex changes
As the changes get more complex, it can be tough to describe them in sufficient detail. For certain kinds of changes, it feels to me as though the best way to load the changed structure is to crawl a staging site with the new architecture. Of course, in general, this means having the whole thing implemented and ready to go, the effort of doing which negates a large part of the benefit of evaluating the change in advance. We have a secret weapon here which is that the “meta-CMS” nature of our SearchPilot platform allows us to make certain changes incredibly quickly across site sections and create preview environments where we can see changes even for companies that aren’t customers of the platform yet.
For example, it looks like this to add a breadcrumb across a site section on one of our customers’ sites:
-1-1.png)
There are a few extra tweaks to the process if you’re going to crawl a staging or preview environment to capture internal link changes - because we need to make sure that the set of pages is identical in both crawls so we can’t just start at each homepage and crawl X levels deep. By definition we have changed the linking structure and therefore will discover a different set of pages. Instead, we need to:
- Crawl both live and preview to X levels deep
- Combine into a superset of all pages discovered on either crawl (noting that these pages exist on both sites - we haven’t created any new pages in preview)
- Make lists of pages missing in each crawl and crawl those from lists
Once you have both crawls, and both include the same set of pages, you can re-run the algorithm described above to get the local PageRanks under each scenario and begin comparing them.
How to compare different internal link graphs
Sometimes you will have a specific problem you are looking to address (e.g. only y% of our product pages are indexed) - in which case you will likely want to check whether your change has improved the flow of authority to those target pages, compare their performance under proposed change A and proposed change B etc. Note that it is hard to evaluate losers with this approach - because the normalisation means that the local PR will always sum to 1 across your whole site so there always are losers if there are winners - in contrast to the real world where it is theoretically possible to have a structure that strictly dominates another.
In general, if you are simply evaluating how to make the internal link architecture “better”, you are less likely to jump to evaluating specific pages. In this case, you probably want to do some evaluation of different kinds of page on your site - identified either by:
- Labelling them by URL - e.g. everything in /blog or with ?productId in the URL
- Labelling them as you crawl
- Either from crawl structure - e.g. all pages 3 levels deep from the homepage, all pages linked from the blog etc)
- Or based on the crawled HTML (all pages with more than x links on them, with a particular breadcrumb or piece of meta information labelling them)
- Using modularity to label them automatically by algorithmically grouping pages in similar “places” in the link structure
-1-1.png)
I’d like to be able to also come up with some overall “health” score for an internal linking structure - and have been playing around with scoring it based on some kind of equality metric under the thesis that if you’ve chosen your indexable page set well, you want to distribute external authority as well throughout that set as possible. This thesis seems most likely to hold true for large long-tail-oriented sites that get links to pages which aren’t generally the ones looking to rank (e.g. e-commerce sites). It also builds on some of Tom Capper’s thinking (slides and blog post) about links being increasingly important for getting into Google’s consideration set for high-volume keywords which is then reordered by usage metrics and ML proxies for quality.
I have more work to do here, but I hope to develop an effective metric - it’d be great if it could build on established equality metrics like the Gini Coefficient. If you’ve done any thinking about this, or have any bright ideas, I’d love to hear your thoughts in the comments, or on Twitter.
SearchLove London 2017 | Will Critchlow | Seeing the Future: How to Tell the Impact of a Change Before You Make it from Distilled